
文/蘇元和
隨著人工智慧(Artificial Intelligence,AI)技術不斷發展和日益普及,2023年ChatGPT又掀起全球熱潮,更讓社會大眾見識到生成式AI的氾濫,如今網路世界假資訊、假影像等充斥著我們的生活,如何具備人工智慧識讀能力是當今重要的課題。
本文專訪長年專攻研究影像辨識技術、機器、深度學習的成大統計所助理教授許志仲,他曾以「精準辨識」郊區不規則環境等,在德國模式識別協會(DAGM)年度樣形式別國際研討會(GCPR)競賽中,從全球53組中勇奪第一;也曾參加歐洲電腦視覺國際研討會 (ECCV) 舉辦的新冠肺炎影像辨識競賽中,打敗28個隊伍拿到世界冠軍;他更是在2018年Deepfake辨偽技術還未受到大眾關注時,就投入研究,可說是台灣學界最早投入該領域的研究者之一。
以下是專訪許志仲教授並探討數位(人工智慧)識讀力的內容摘要:
《全民查假會社》問(以下簡稱問):請問人工智慧AI深度偽造氾濫,民眾如何辨識假影像、假照片,有無關鍵的觀察、技巧?
許志仲答(以下簡稱答):
針對影像上,除了媒體等報導上提供很多辨識技巧之外,舉例常見的線索,例如毛髮或者是表情有沒有不自然等。但另外我提供一些辨識技巧,其中一個比較特別的線索是,我們看Video影片或照片時,需要觀察照片影片的來源,比方說它的發文者是誰,或者從哪一邊轉貼來的,其實這一些線索也蠻重要的。
我們研究發現,事實上有一些影片可能已經以假亂真到看不太出來,或者影片品質太低了,導致觀察不出深度偽造的線索,但這些影片經常是由幾個常見的帳號所發表或轉貼;又或者,這些偽造影片通常都會搭配類似的行為 (如文字描述、Tag等),都可以運用來輔助深度偽造影視訊的判斷。
因此我們就設法去從那些社群媒體Social Media的資訊裡,去尋找這一個影片或這一個照片是否為真、或假的輔助證據,這裡要說明的是不見得社群平台上所寫的文字都是假的,我要強調的是某些帳號的行文手法、或者是他的那一個帳號本身就是高嫌疑感,所以從這個帳號出來或轉貼的影片或照片就是比較具有嫌疑的、偽造的。
閱聽大眾可以去觀察「帳號本身」是不是「經常」發同樣類型的影像或照片,雖然我們知道有帳號資訊可觀察,但我們卻很少去觀察照片或影片背後的帳號來自於哪裡,因此對「帳號的來源」保持警覺意識,是打假的重要一步。
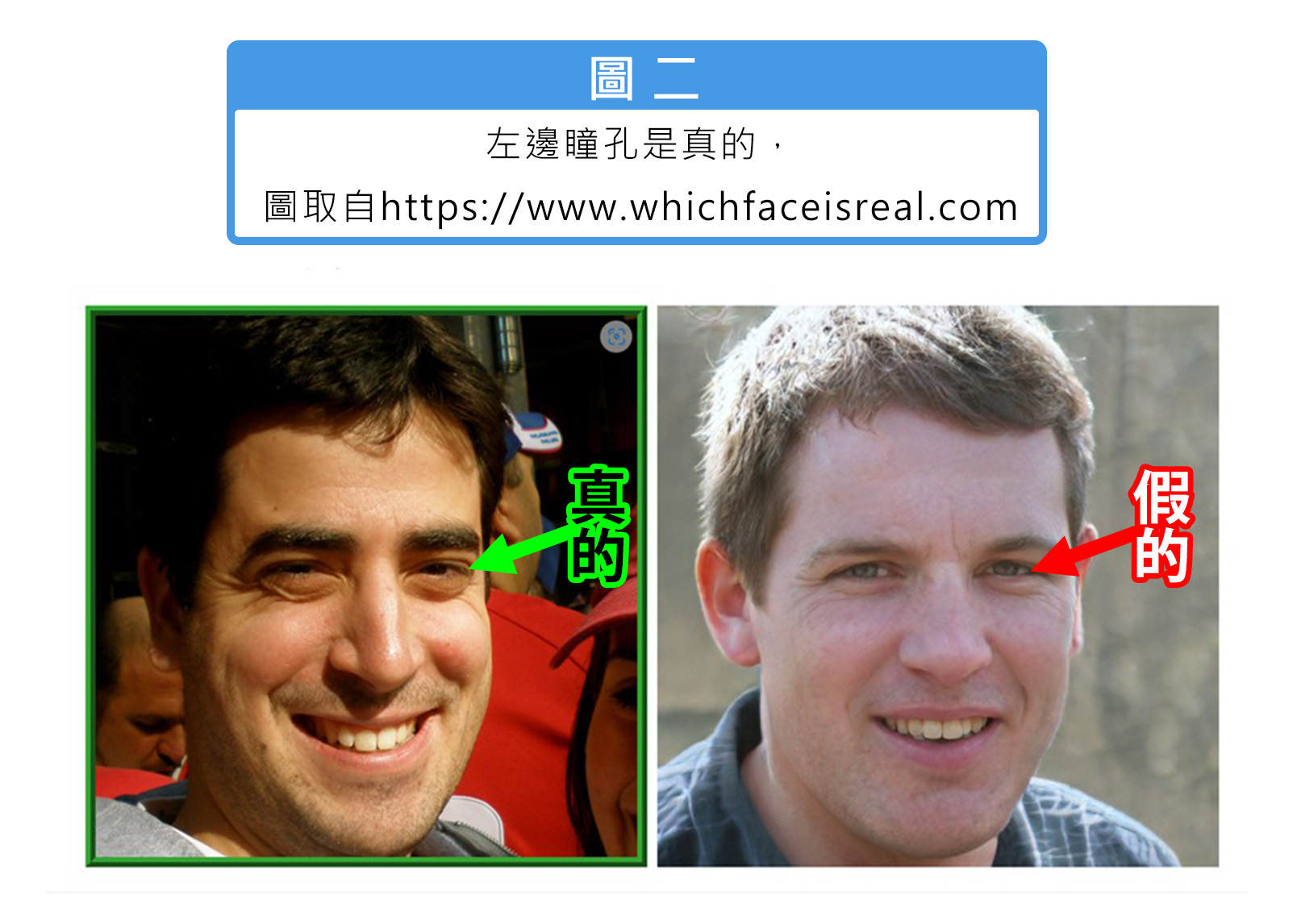
另外,前清後矇的照片,被稱為「淺景深」的效果。現在較為流行的AI,也就是擴散生成模型 (Diffusion-based models) 生成影像或照片背景通常是散景 (模糊的),如下圖一所示。通常我們人眼對前景物體較為敏感,而背景就容易忽略,再加上多素是散景的關係,若沒有先抱持著「這可能有問題」的想法,就會忽略去觀察之。因此,這個模糊背景中可能隱含著偽造的線索,比方說,一看就知道是直線的物件,但它可能斷掉、會有彎曲,這個也很常出現於背景糊糊的生成照片。
此外,另一個判斷線索就是瞳孔的部分,研究發現AI生成技術偽造的眼睛瞳孔不見得是純圓形的,可能會扁或者是有一些奇怪的形狀(下圖一),尤其是黑色眼珠子的部分不是純圓的,相反地,我們一般人正常都是圓的、圓珠裡呈正常放射狀。
以上三個關鍵的觀察仍是目前可作為辨識深度偽造的重要線索,但隨著生成模型的能力越來越提升之後,模糊背景與瞳孔的兩個錯誤就不易成為線索了。

問:承上,我們知道有帳號發布可疑影片與照片,但一開始可能無法知道帳號來源的可信度,那該怎麼辦?
答:一開始你(社會大眾)還是要觀察一下,尤其是對一個帳號陌生與不認識時,除非你本來就認識該帳號,或者該帳號本來就已經在網路上惡名昭彰了。但如果以上都沒有的情況下,我講的就是那種比較極端,你都沒看過,但你花一段時間來觀察此帳號的發文動態,還是觀察得出來這個帳號是否發文可能容易偏頗,甚至成為深度偽造影視訊的傳播者 (有意或無意都有可能),我認為,我們人對於觀察這個能力是蠻強的。
問:有沒有什麼工具或技巧或程式,可以協助我們一開始就可以判別這個帳號是假的?
答:我們是有正在開發一個就是類似判別的工具,但因我們開發的成果還沒有發表論文,所以還未公開這個工具。另外我想強調的是,帳號本身不見得是真假,他有可能是真的帳號,只是因為該帳號在社群媒體平台上可能相對偏頗,因此就可能淪為不實影視訊的傳播者之一。
通常有一些輔助工具,例如像一些工具做網軍的偵測,做一些有政治意圖傾向的言論的偵測器,那些偵測器只要稍微改一下,是有辦法判斷帳號是不是可能常常發這一類假新聞的。但這個不是我研究的領域。
問:可否補充說明你們尚未發表論文、還未公開的辨識假帳號的工具,其研發的程度到哪?
答:這個研發基本上就是我們已有一定的資料量,首先要有資料我們才能去驗證,我們目前的研發成果就是發現,我們收集了大量社群媒體中的深度偽造影片,只有用影片或照片的偵測效果其實都沒有很好,過去的方法偵測以最好的模型來偵測,大概也是只有六、七成左右的效果,這個數字並不高,偵測效果遠低於學術研究用的資料庫,這也意味著現實生活中的深度偽造影片還有很多困難點。但我們現在加入社群媒體的資料,例如:加上社群媒體的評論、帳號ID、追蹤人數、被追蹤的人數等常見線索,我們把這些線索都融合成一個資料之後,用一個AI機器去學習,我們稱它叫「個人資料」的特徵,我們把這些特徵、影片或照片的特徵融合一起,再交給AI來判斷,結果我們發現加個人資料的特徵後,其準確率可從六、七成上升,到現在至少有八成五的準確度。這就代表說,這些「個人資料」線索是有用的。
我們目前正在做的就是希望可知道為什麼準確度提升那麼多,緊接著我們想回溯到底是評論重要,還是個人帳號重要。目前這個層面,我們還沒去做,但我們要往這方向去繼續研究發展。
問:承上,可以從粉絲數少,判斷成是偽帳號嗎?還是有其它關鍵的判斷?
答:我們要去建議、去學習判斷假帳號其實是真的很難,因為首先要先知道他是網軍,可是網軍不會說自己是網軍,所以他不會有真正的答案存在,結果就會造成收集不到這種資料,沒有辦法去學習,所以我們的作法並不是這個樣子。
我們的做法是假設我知道有Video是假的,然後這個Video是哪幾個帳號發出來的,可能是一個或是多個,這就代表說這個帳號發了這一個假的Video,但這個帳號本身是不是假的並不重要,帳號亦有可能是真的,只不過他的個人行為是「看到任何新聞就趕快轉發,不會做任何篩選,所以不見得是刻意做假,但是他可能成為幫兇之一,因為他的行為都直接轉貼。」
所以,我們的研究是去抓、去掌握,什麼樣子的行為會導致這樣子的照片傳播出來,但這個行為本身的後面帳號不見得是網軍,也不見得是假的,所以在這樣情況之下,我們就不需要去對帳號本身去做怎樣的標註。
總結來說,我們拿Social Media的資訊來做輔助參數值而已,而不是拿Social Media資訊的真偽來判斷。
問:你剛剛講到一個帳號的粉絲數、追蹤數都只是一個參考數字對不對?只是輔助了解使用這個帳號可能有哪幾種傳播行為的樣態對不對?
答:對對對。
問:那目前研究機器人正在學習?
答:對沒有錯,這個就是我們自動在學習的,確實發現機器人有在學習,所以我們才會想說要把這個方向再做好一點發展。
問:請再補充多一些說明,機器人學習已到達怎樣的層面?
答:數字客觀來說,就是辨識正確率有上升,但接著我們很想知道的是為什麼而上升,我們正在找上升最主要的關鍵是來自於Social Media裡的哪一些資訊。如果找到了,我覺得就會很有說服力,除了可以有一個系統,第二還可以說明以後可能要多重視社群媒體的那些線索,整體來說,我覺得會蠻有幫助的。
另一個很重要的議題是刻意的深度偽造攻擊。簡言之,Deepfake Detection深度偽造辨識技術最主要的困難就是對抗攻擊的問題,這樣的技術不僅可以騙過人眼,更可騙過AI系統,現今大多數的研究都束手無策。為了解決這個問題,我們研究首次提出一種全新的對抗防禦機制,即欺騙機制。這是一創新方法,可同時有效地偵測深度偽造的人臉,而且不受任何對抗雜訊的影響。








